What each module does.
The modules from the pipeline for pulling a raw sound file apart for musical analysis. A series of pair modules extracts components of the waveform and interprets them alongside web and user-derived context, in order to isolate musical elements via the waveform — spectra, partials, transients, formants, residual — so that each musical component can later be inspected, resynthesised, and reasoned about on its own terms.
The engine alternates between: a binary module (the A side) reads the audio file, and a (B side) web/user module, running in tandem. Using what’s gleaned from both the binary data alongside the cultural context and any user input, a moment of conference (the chat) reconciles what is true across all domains before the next module begins (drums are here in the mix, lead vocalist is a woman, etc.).
The engine holds attributes provisionally — recognised as repeated and regular, but not yet given a specific name. Each conference is where the User directs to commit a name, based on the combined evidence from the binary side (what's measurable in the audio), the web side (what's credited, claimed, written about), and the user side (what the human somatically or experientially confirms or corrects). The conference recurs at the end of every module pass — it's the connection or transference between the gleaned and the discussed — and each round of conference and reconciliation hands its resolutions forward as priors for the next round. In this way it is a collaborative effort, and the greater effort a user brings to the space, the stronger and more quality the final analytical output will be.
Binary · 1A · ↔ 1B
Spectrogram & spectral roster
first look at the audio · 55 named bands · 7 functional roles
The audio file you give the engine — an .mp3 or .wav — arrives as a long list of amplitude samples over time. That’s a waveform: a squiggly line saying “the speaker cone was here at this instant, and there at the next instant.” Useful, but flat: you can’t tell from a waveform alone where the kick is, where the voice sits, or what frequencies the room is humming at.
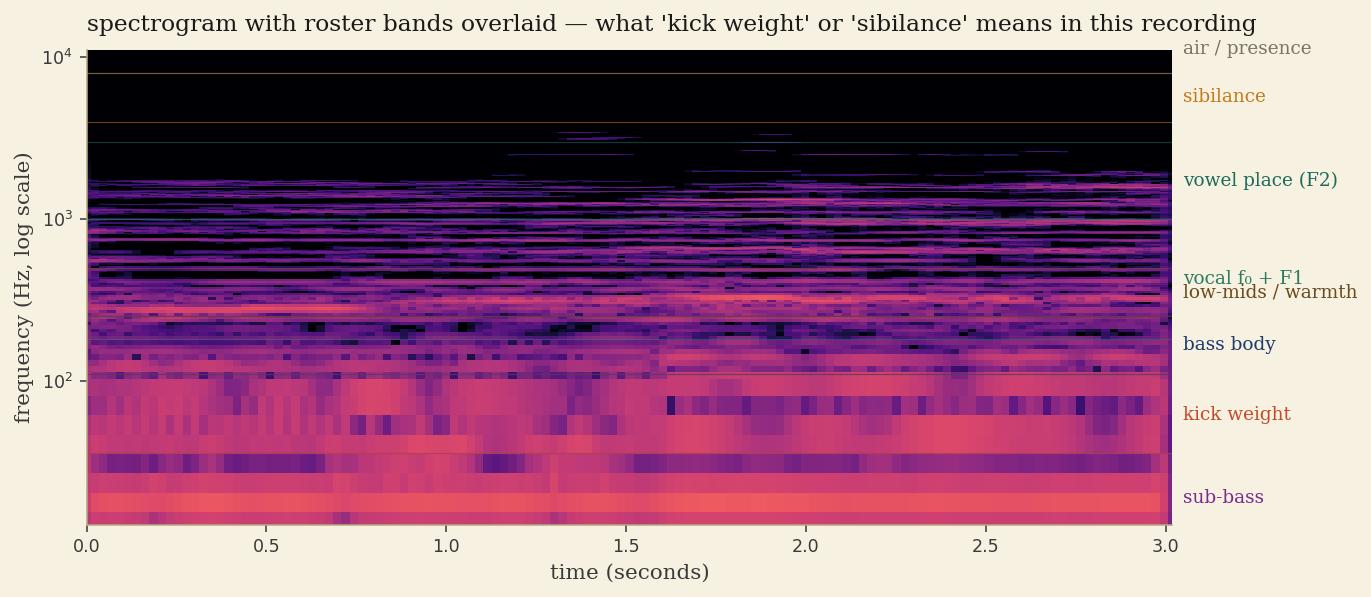
The harmonic roster — 55 named bands, 7 roles
The engine doesn’t see anonymous frequency bins; it sees these named slots. When a later module says “kick weight dropped at 2:14,” it’s pointing at one specific column in this table. Hover any chip for its typical sound profile.
Each band lights up where it lives on the audible spectrum. Click any chip or band to hear a short sine at its center frequency.
What it writes. The spectral roster — a permanent, named record of what’s living where in the recording. The engine doesn’t commit names to specific events yet; it commits the vocabulary the rest of the pipeline will use to point at things.
Web / User · 1B · ↔ 1A
Initial context
metadata · credits · claimed equipment · reception language
While 1A is running its first FFT, 1B is running its first web pass — reading everything around the file rather than the file itself. The two passes start at the same time and proceed independently until the first conference reconciles them.
Be honest about what this is. Critics use these words inconsistently across decades and genres — one reviewer's "warm" is another's "muddy" is another's "fat." This step is a loose heuristic that gives the conference a rough prior to test the audio against, not a measurement. It sits next to rigorous LPC and partial-tracking on this page, but it does not earn the same confidence; treat reception-match scores as a sanity check that can be overruled by any of the four other filters at the next conference.
What it writes. A context bundle — { metadata, credits, claimed_equipment, genre, genre_baseline, reception_profile }. Note: this is held tentatively — the engine knows the credits claim certain things; whether the audio confirms them is for the next conference to test.
Conference · 1 · first reconciliation
Reconcile: roster vs. genre baseline
“does what the audio shows roughly match what we’d expect from this kind of record?”
Now the binary and the web get into a room together. The binary brought its thesis — every frequency band it could see active in the recording. The web brought a baseline — what records of this kind usually sound like. The conference is where they argue out three questions, in order: what's unusual in the audio, whether the credits back up the unusual bits, and who wins when they disagree. A snare 4 dB louder than the genre average is unusual. A sibilance band sitting outside the typical range is unusual. The records worth caring about are mostly unusual.
What it commits. A shortlist of marked bands — each with what the audio said, what the context said, and how confident the engine is. Everything downstream carries these marks forward as priors.
Binary · 2A · ↔ 2B
Trajectory mode — sinusoidal partial tracking
peak-pick · frame-to-frame match · continuous partials
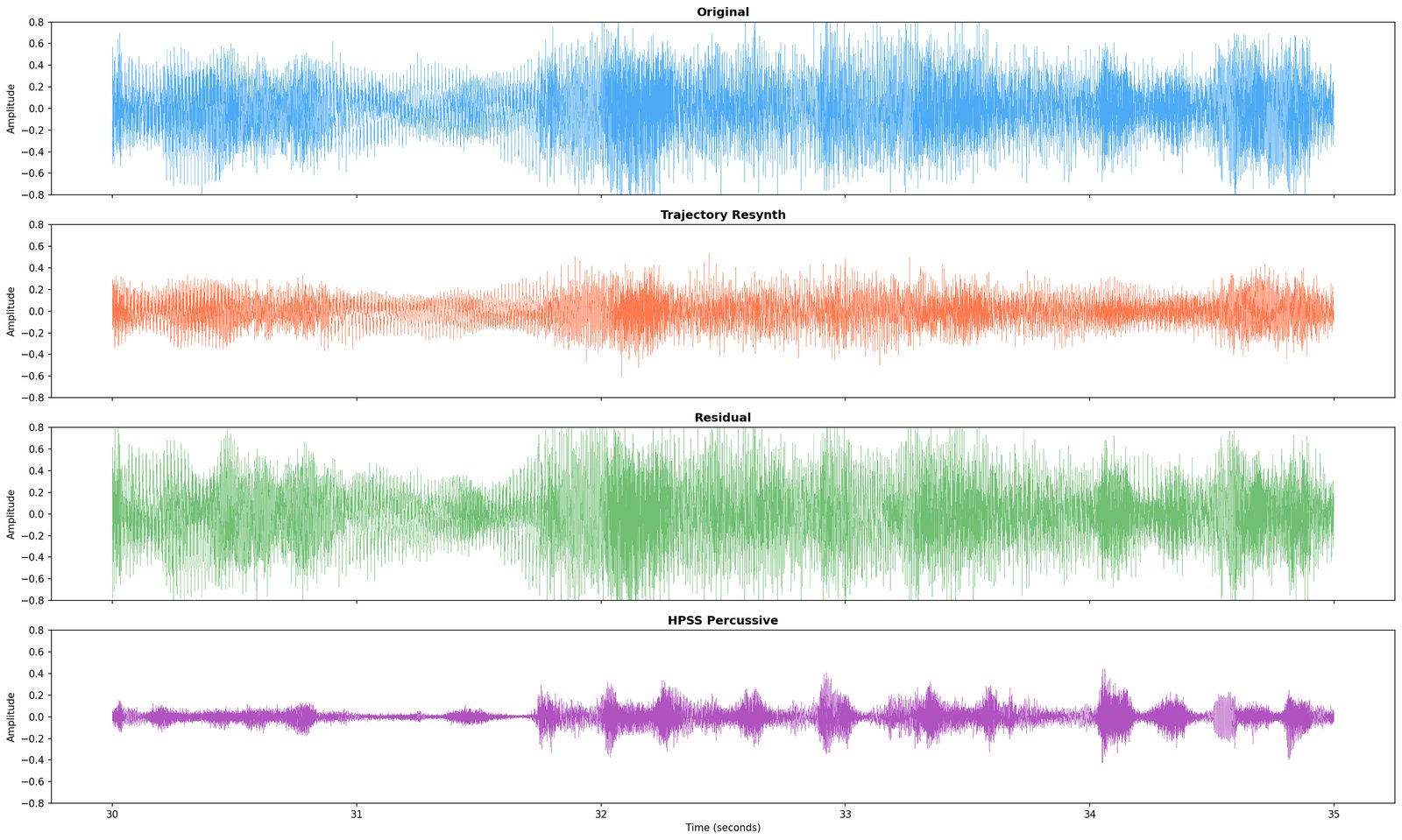
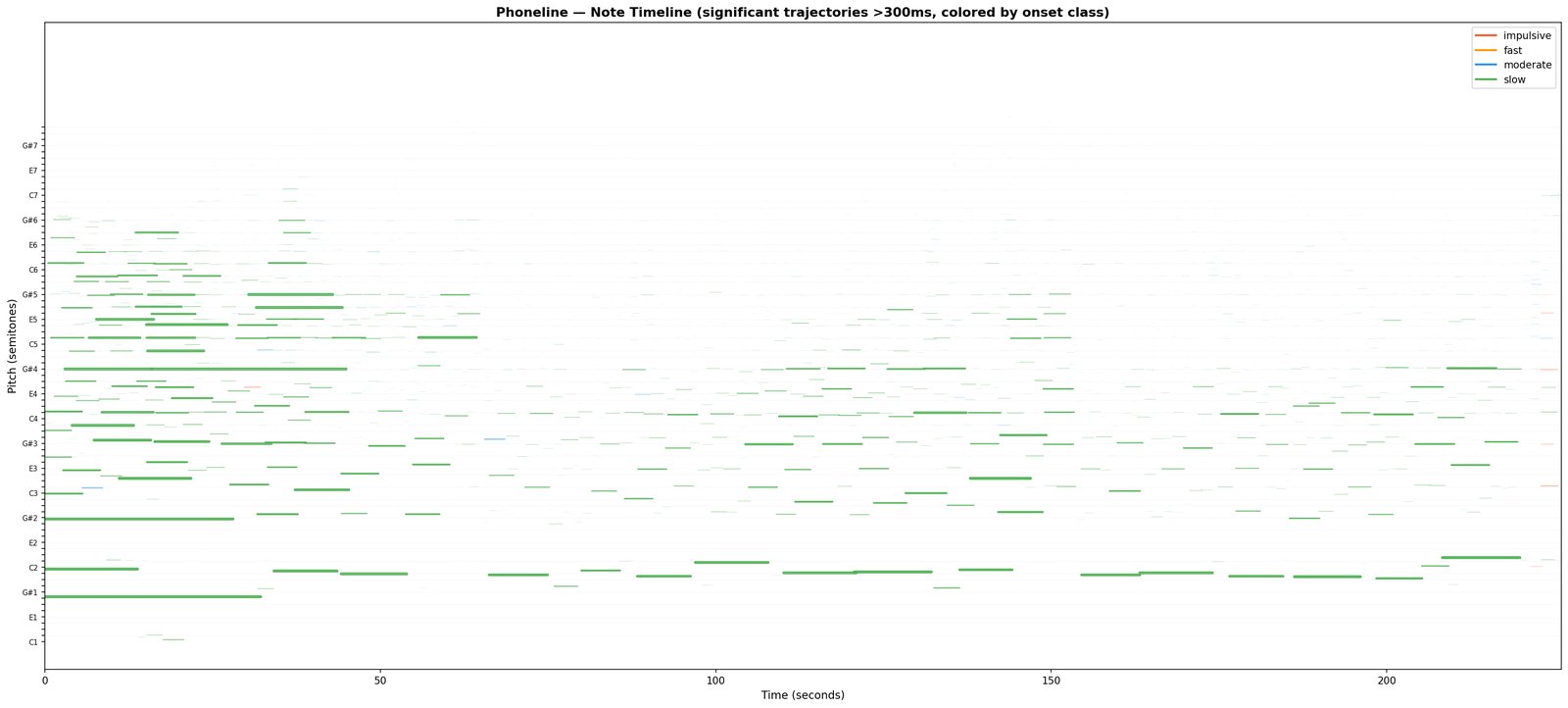
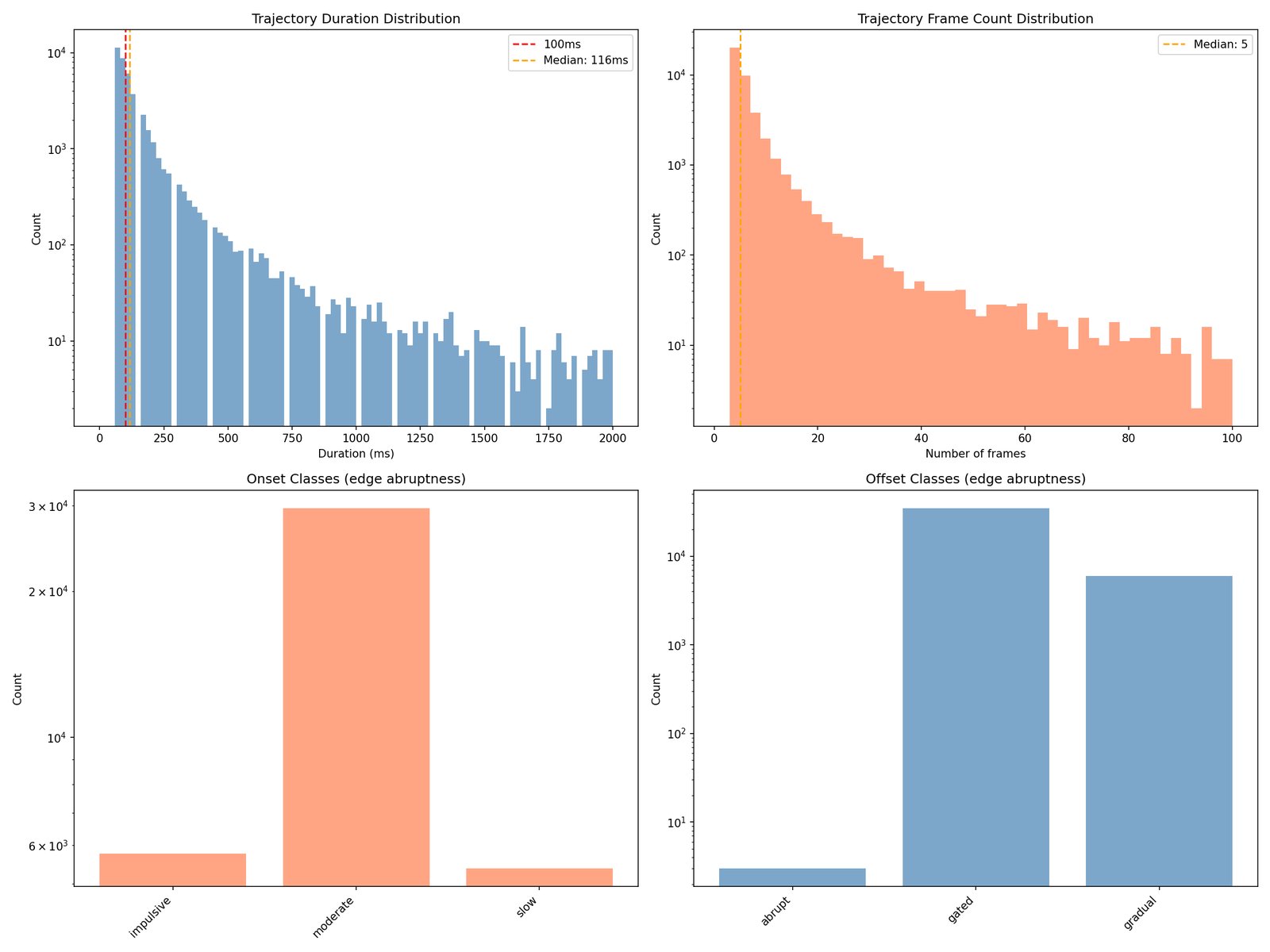
Where 1A flattens the recording into a time-and-frequency picture, 2A asks a different question: which individual tones are sounding right now, and how do they move? A four-minute song typically produces 30,000–50,000 of these tracks. This isn’t a new engine — it’s the binary analysis of 1A re-entered at a finer resolution.
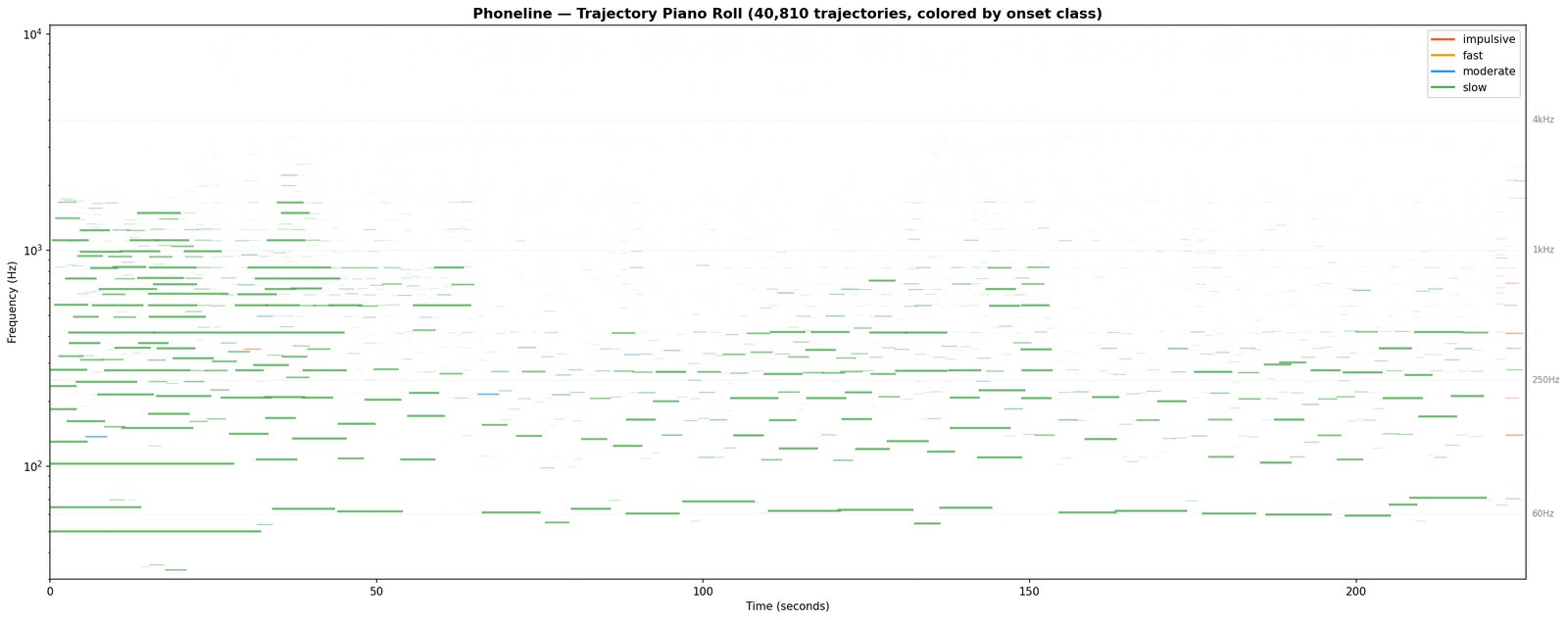
What it writes. The trajectory bank — tracked tones with their pitch / loudness / phase histories and tentative role tags. The pattern is identified; the name is held back until 4.
Web / User · 2B · ↔ 2A
Instrumentation-granular context
“is it drums?” · “is there a synth on this record?” · user input
2B runs in tandem with 2A. By now the web pass has trajectory patterns to ask specific questions about. This is where the web layer’s curiosity gets more granular than the initial artist+title pass.
What it writes. A refined context bundle — instrumentation-specific priors and user corrections, carrying forward to conference 2. The web side now knows what it’s meant to be looking for, and the user has had a chance to disagree with the engine’s tentative assignments.
Conference · 2 · second reconciliation
Commit instrument names
“is that 220 Hz blob the bass, a kick rumble, or a low synth?”
The binary side hands over a stack of tracked tones. Each one needs a name. A 60–110 Hz line with no upper harmonics is almost certainly a kick rumble. A 180–400 Hz line with a tall harmonic stack is almost certainly a vocal candidate. The web side has the credit sheet — what instruments are even supposed to be on this record. The user steps in for anything weird ("that bright pad isn't a string section, it's a CS-80"). Same three filters as before — what's unusual, does the context agree, who wins — but now applied to single tones rather than whole frequency bands.
What it commits. Per-tone role tags. This cluster is the bass. This cluster is the lead vocal. These short pitched events are still unclassified — flagged for a later pass. From here on the engine can speak the names of the things in the mix.
Binary · 3A · ↔ 3B
Percussion & onset extraction
per-element onsets · ghost-note discrimination
Where 2A catches pitched tones, 3A catches the hits — kicks, snares, hi-hats, claps, rim shots, room slap, anything short and percussive. Each hit is pulled out as its own event with a tentative label.
What it writes. A per-element percussion timeline with tentative labels, ready to be checked by 3B.
Web / User · 3B · ↔ 3A
Kit-granular context
live kit? 909? 808? sampled break? · per-hit user check
The web/user layer at this granularity is asking: what kind of kit is on this record, and is every hit 3A surfaced really what it says it is?
What it writes. Kit-type priors, per-hit user confirmations / corrections, ready for conference 3.
Conference · 3 · third reconciliation
Commit the percussion timeline
“snare or rim shot? ghost note or bleed? where exactly does a kick end?”
The fun one. The binary side found every transient in the recording and proposed a name for each — kick, snare, hat, ghost note, clap, rim shot. The web side knows what kit the record was tracked with (live kit? a 909? an 808? a chopped break?). The user goes hit by hit, sorting the edge cases: where does a snare end and a rim shot begin? Is that ghost note real or a hi-hat bleed? Is that "kick" actually a low tom? A label survives if all three agree — binary signature, kit-type prior, user ear. Anything that fails one of the three gets re-labelled or dropped.
What it commits. A finished per-element percussion timeline with confirmed labels and gap statistics on the bits the engine wasn't sure about. Now beat-tracking won't get fooled by ghost notes, swing measurement knows which hits to compare, and the residual won't mistake a snare bleed for a vocal leak.
Binary · 4A · ↔ 4B
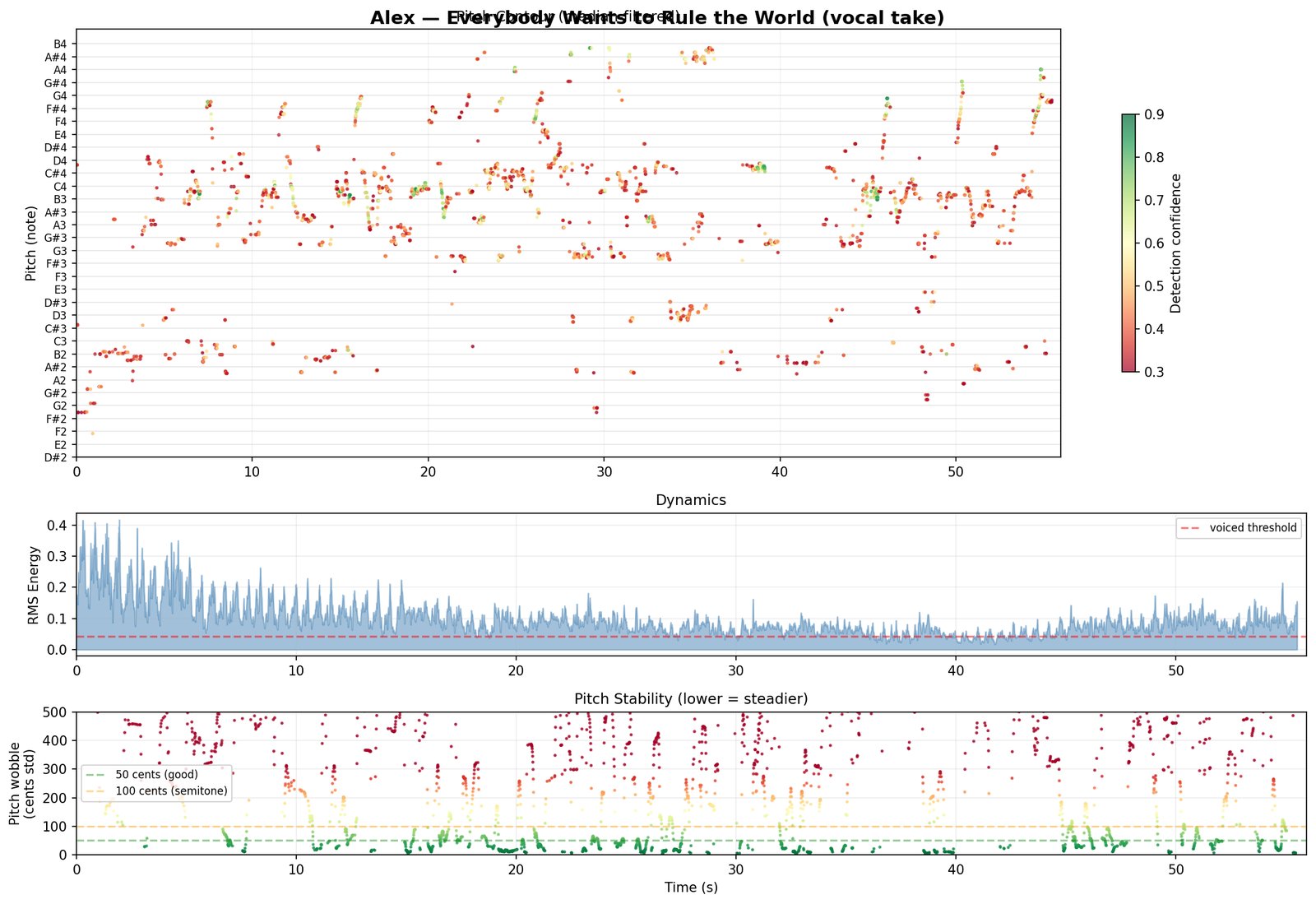
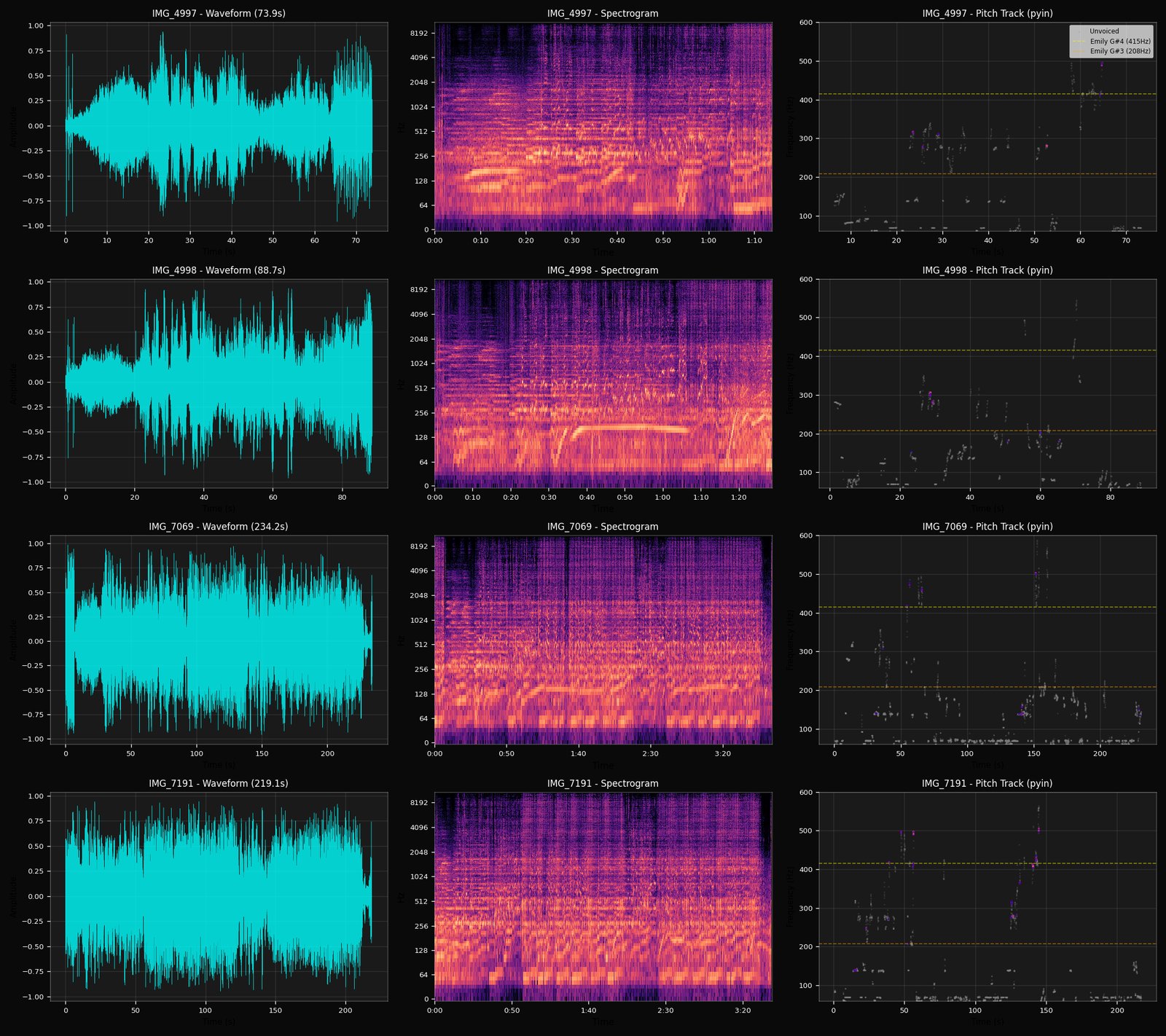
Vocal isolation & LPC formant extraction
200 Hz–4 kHz band · linear-predictive coding · F1·F2·F3
With drums committed (at Conference 3) and the harmonic roster accounted for non-vocal pitched elements (committed at Conference 2), what’s left in the vocal band is close to an isolated voice. 4A pulls out the vocal-tract resonances frame by frame.
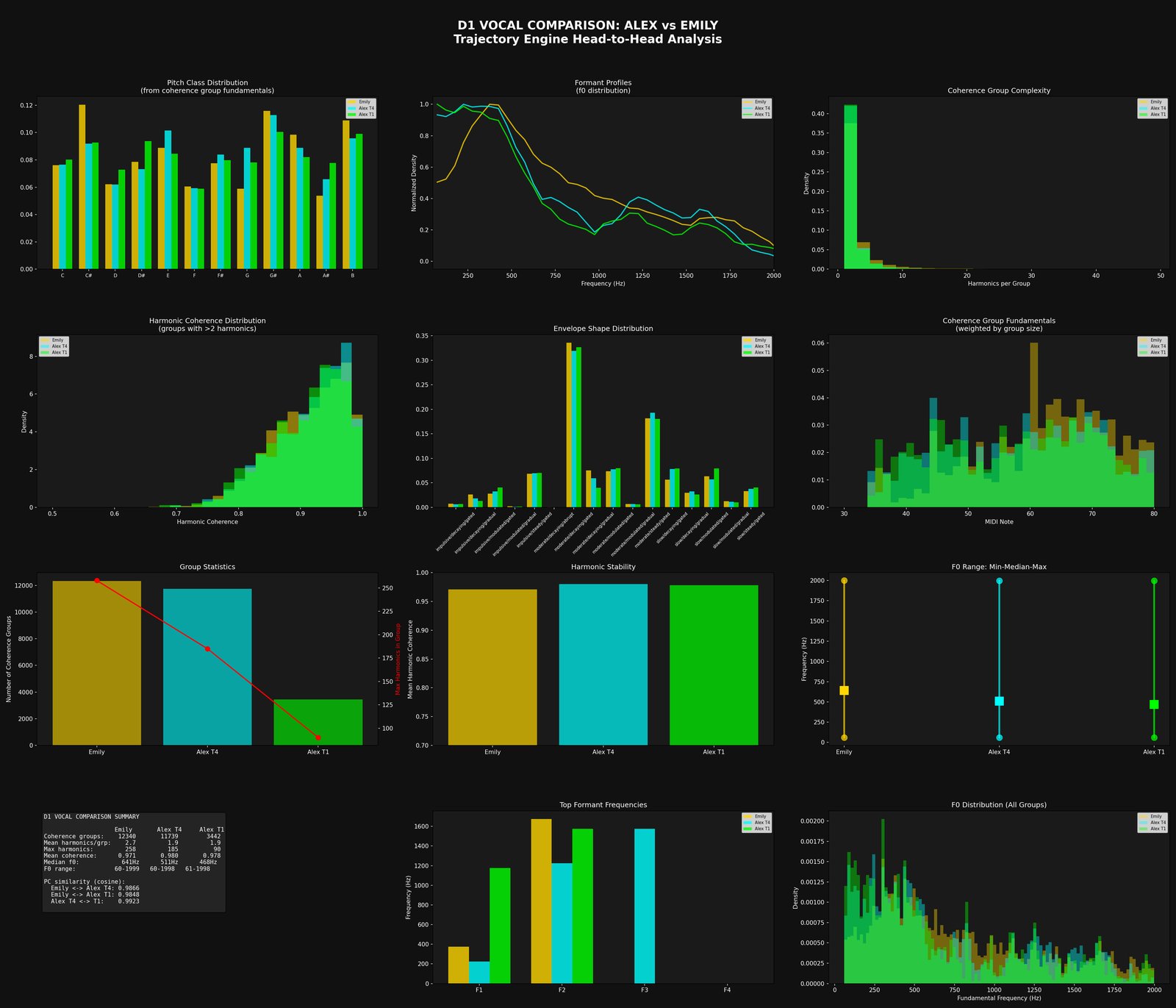
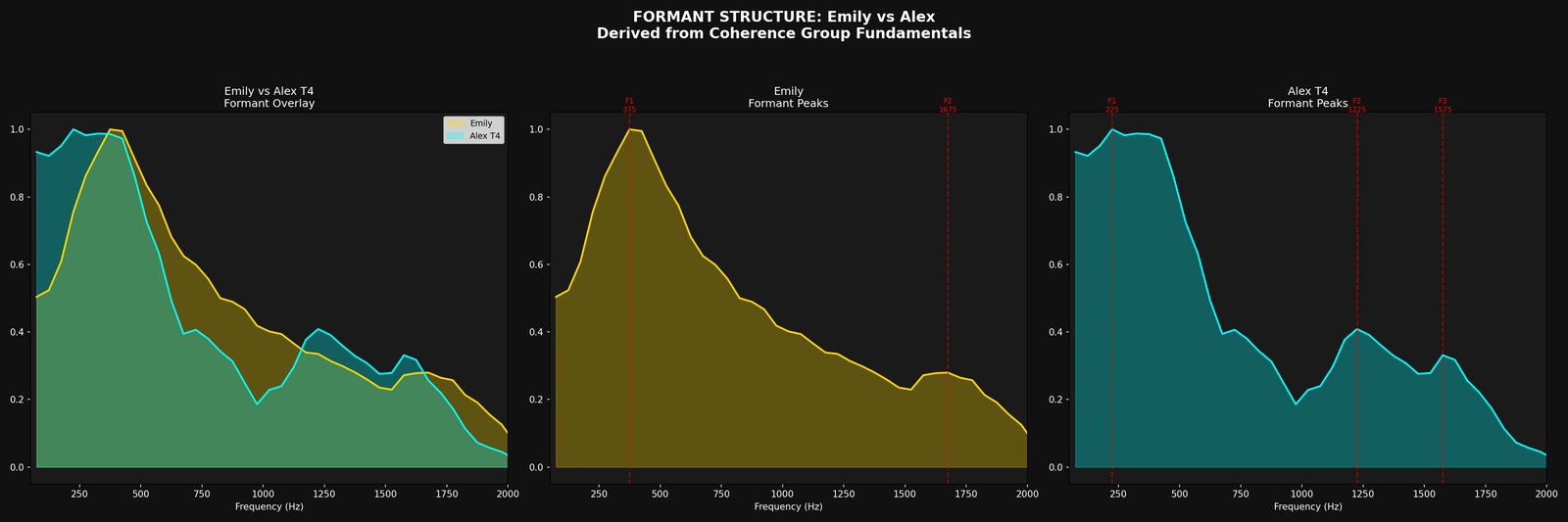
What it writes. F1/F2/F3 trajectories, a voiced/unvoiced flag, and a tilt value held tentatively until 8.
Web / User · 4B · ↔ 4A
Singer-granular context
is this credited singer X? · user comparisons against reference takes
4B asks: is this the singer the credits say it is? The formant trajectories 4A just produced become a fingerprint to check against.
What it writes. Singer identity priors and user comparisons, ready for conference 4.
Conference · 4 · fourth reconciliation
Commit the vocal extraction
“is this the singer the credits claim — and do their vowels match their other recordings?”
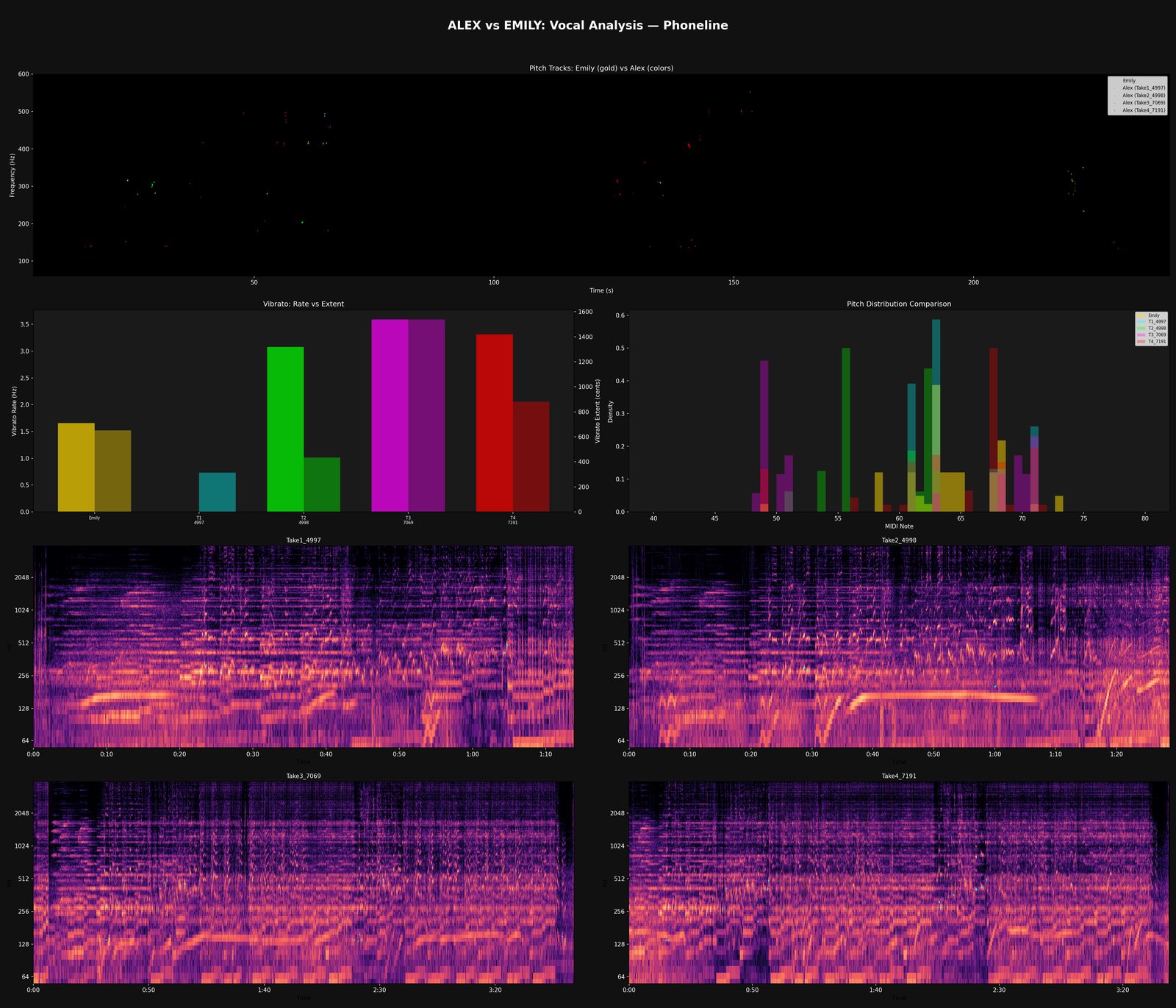
The binary side handed up its best guess at the main wave shapes of the singer's voice — the three formant peaks (F1, F2, F3) that shape every vowel, plus a "tilt" figure that captures the singer's anatomy at a body level. The web side checked the credits to find out who's supposed to be singing, and pulled up any reference vocals the engine has analysed from this singer before. The user listens to the isolated voice and gives the verdict. The conference is where the engine's guess gets calibrated against the credit, the reference recording, and your ears. If they agree, singer identity is locked. If they don't — credits say singer X but the tilt doesn't match earlier X recordings — the disagreement is recorded and carried forward as a flag, not silently overwritten.
What it commits. A finalised vocal-extraction record. Tilt becomes a stable per-singer fingerprint the pipeline can reference on every future recording — the same vocal anatomy showing up across different songs is one of the strongest identity signals the engine has.
Binary · 5A · ↔ 5B
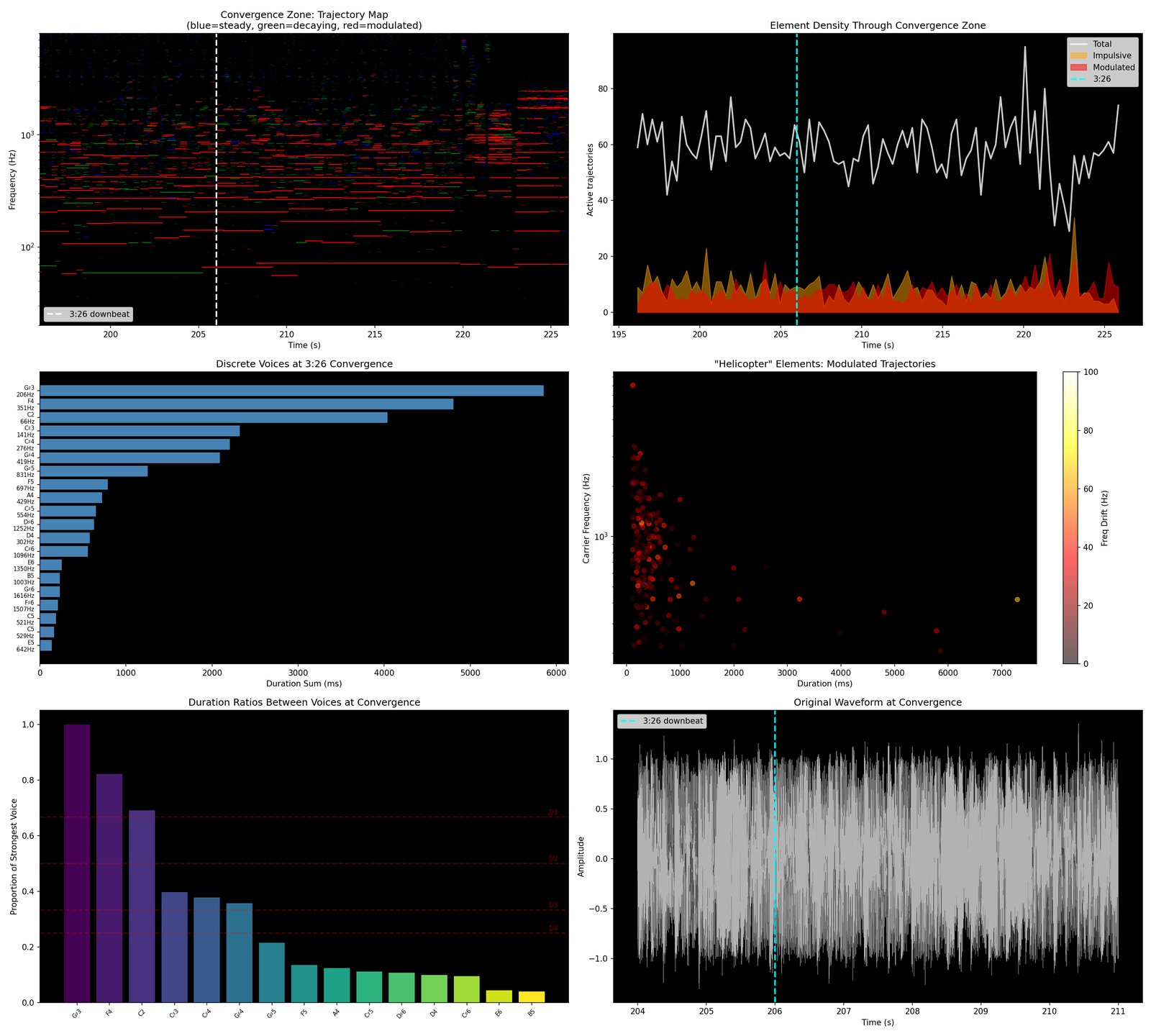
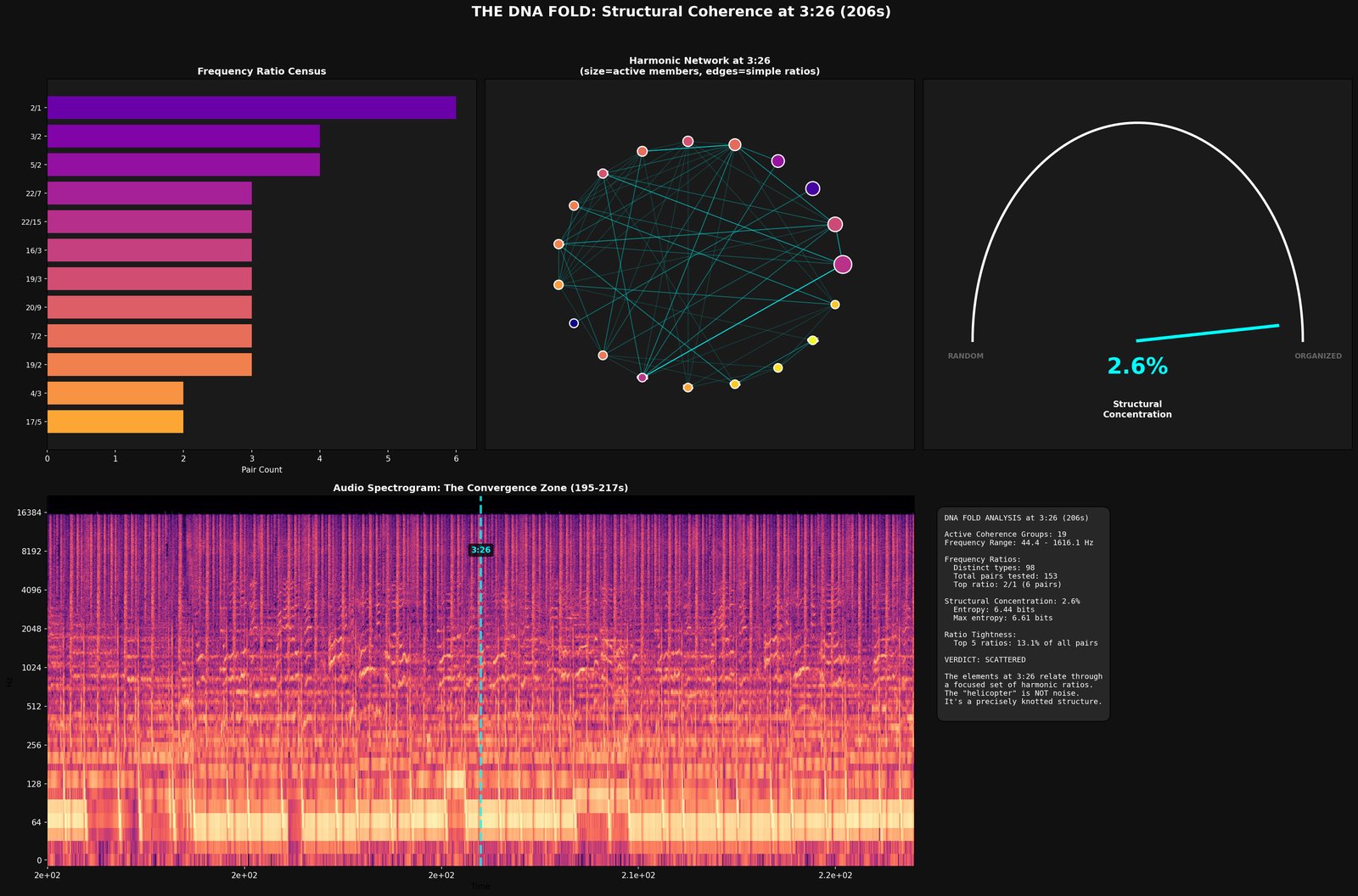
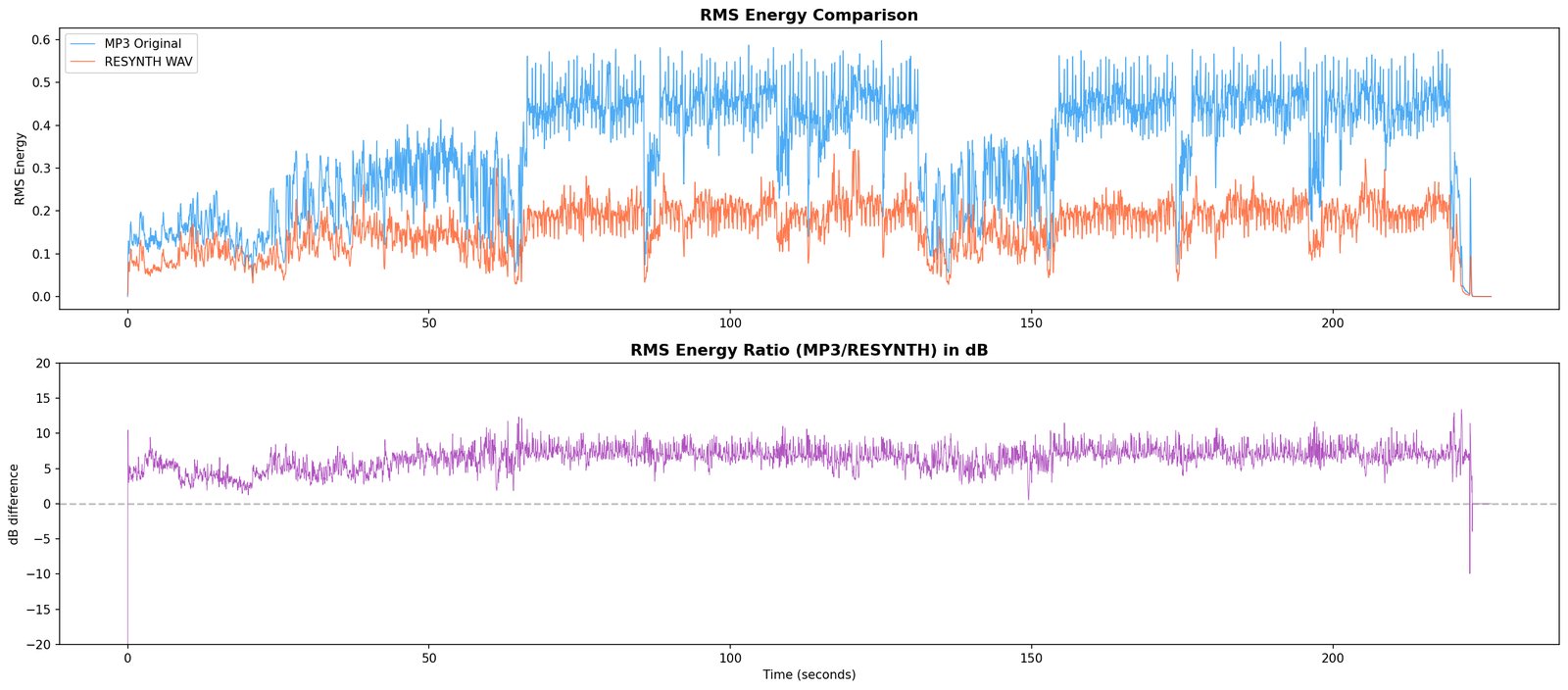
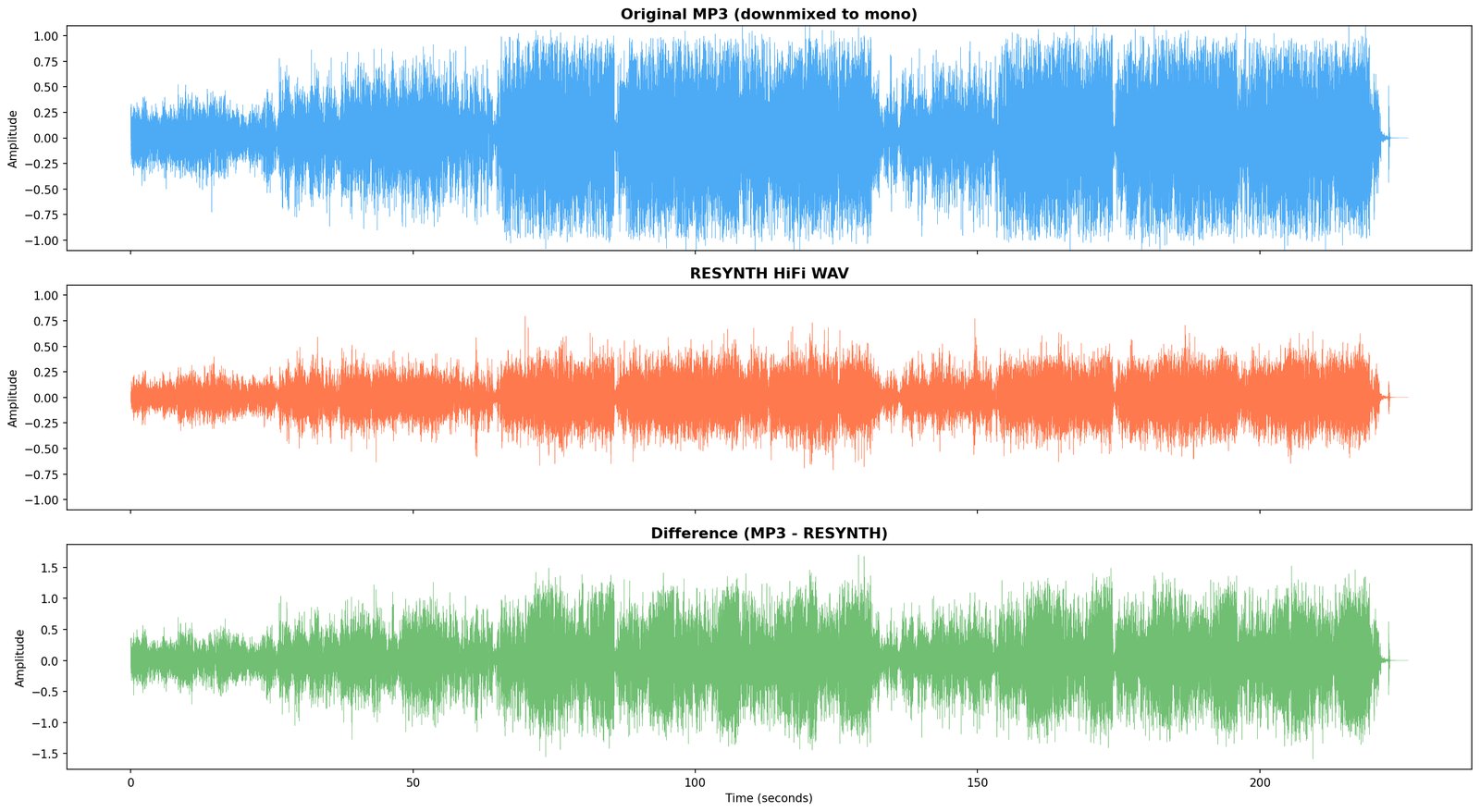
D1 — diagnostic resynthesis & residual
resynth from parameters · original − resynth = residual
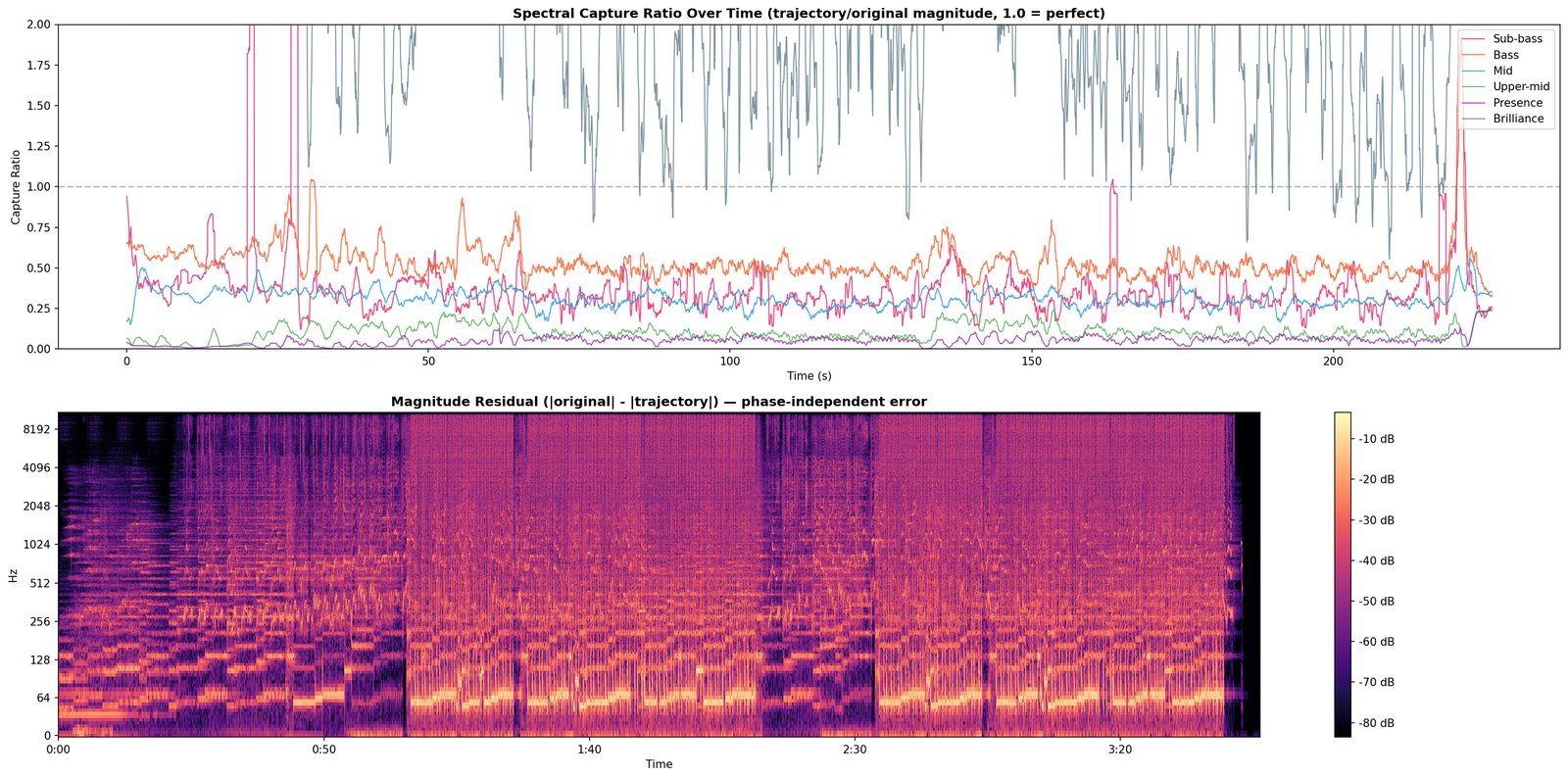
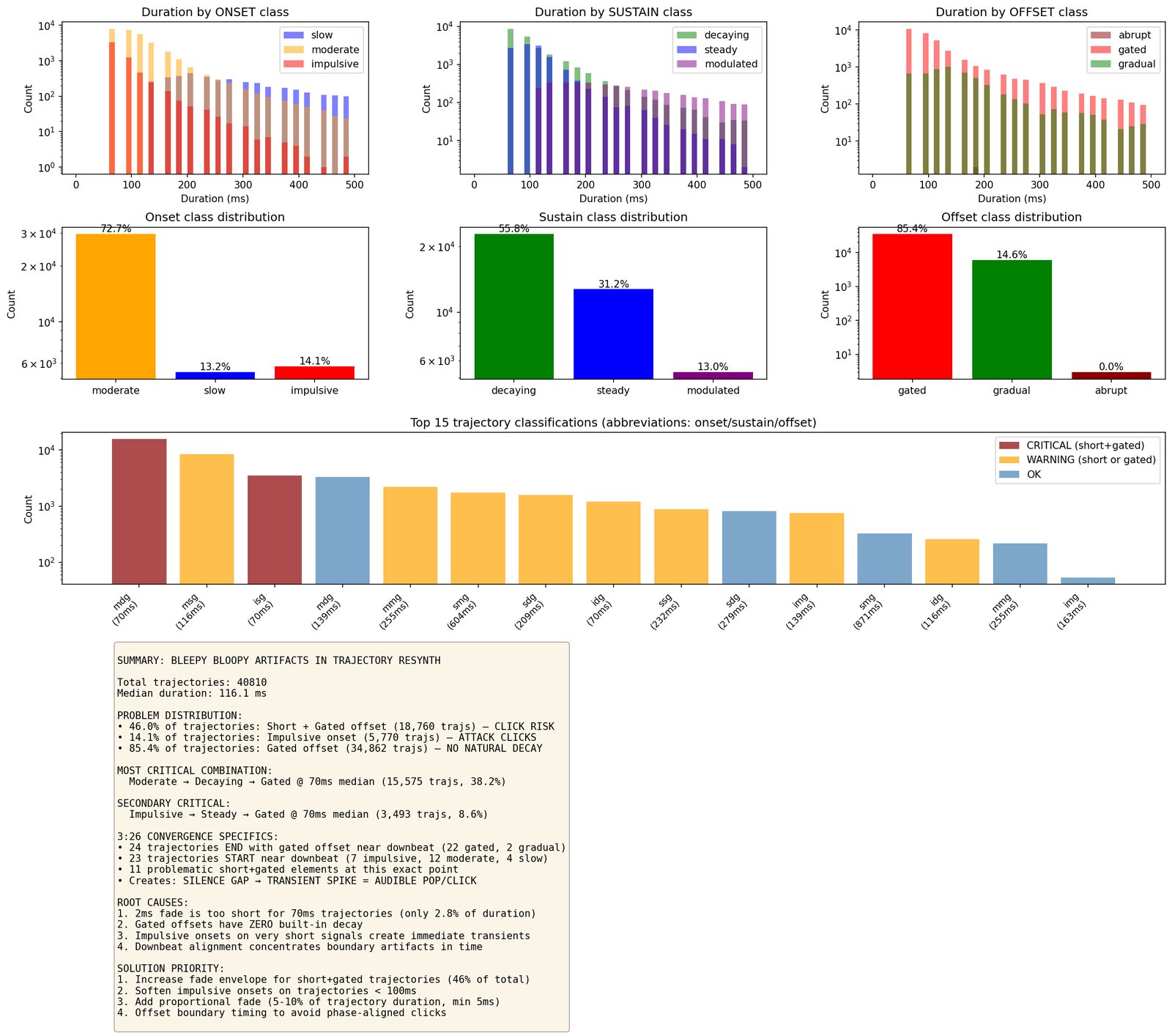
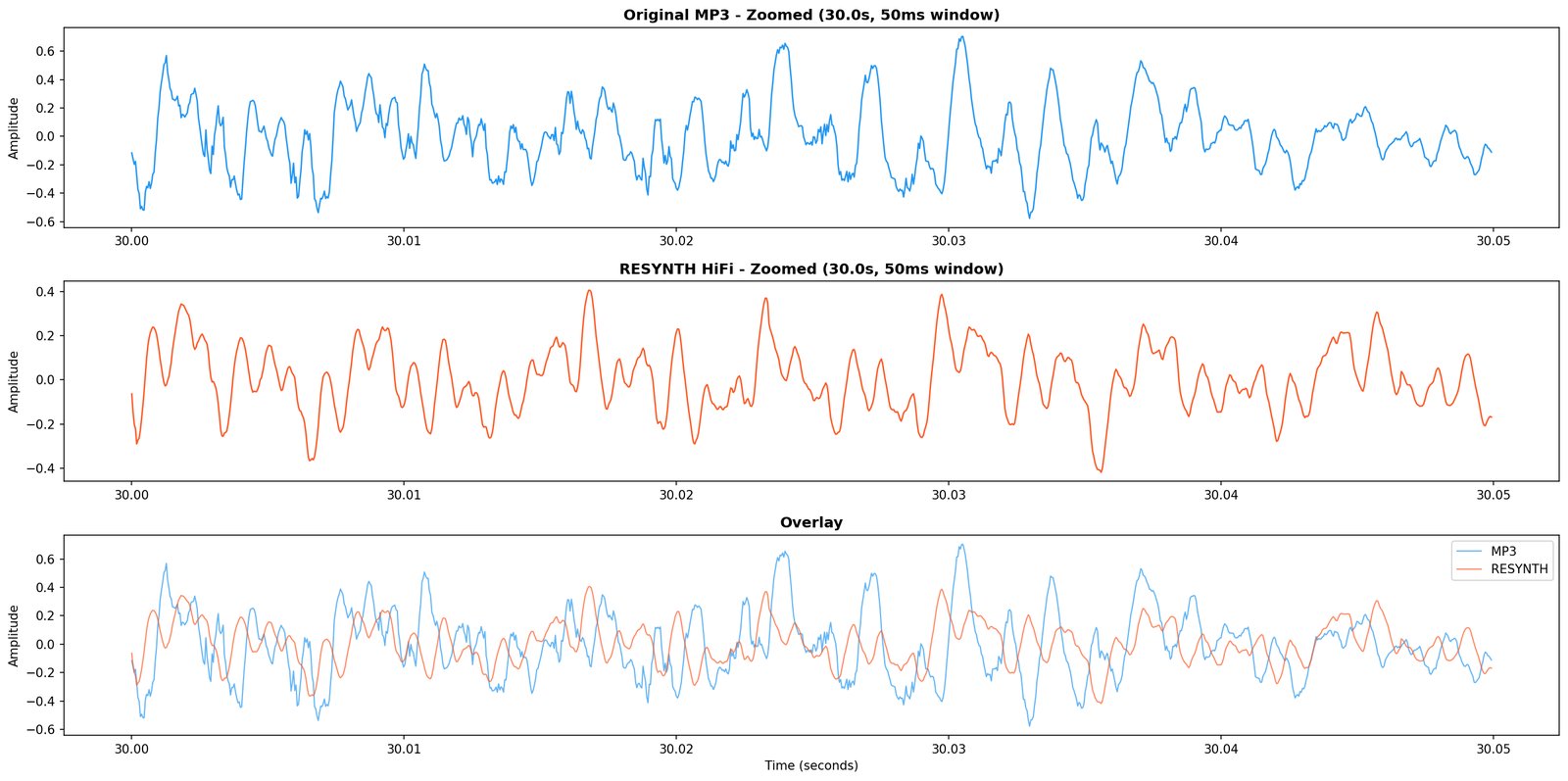
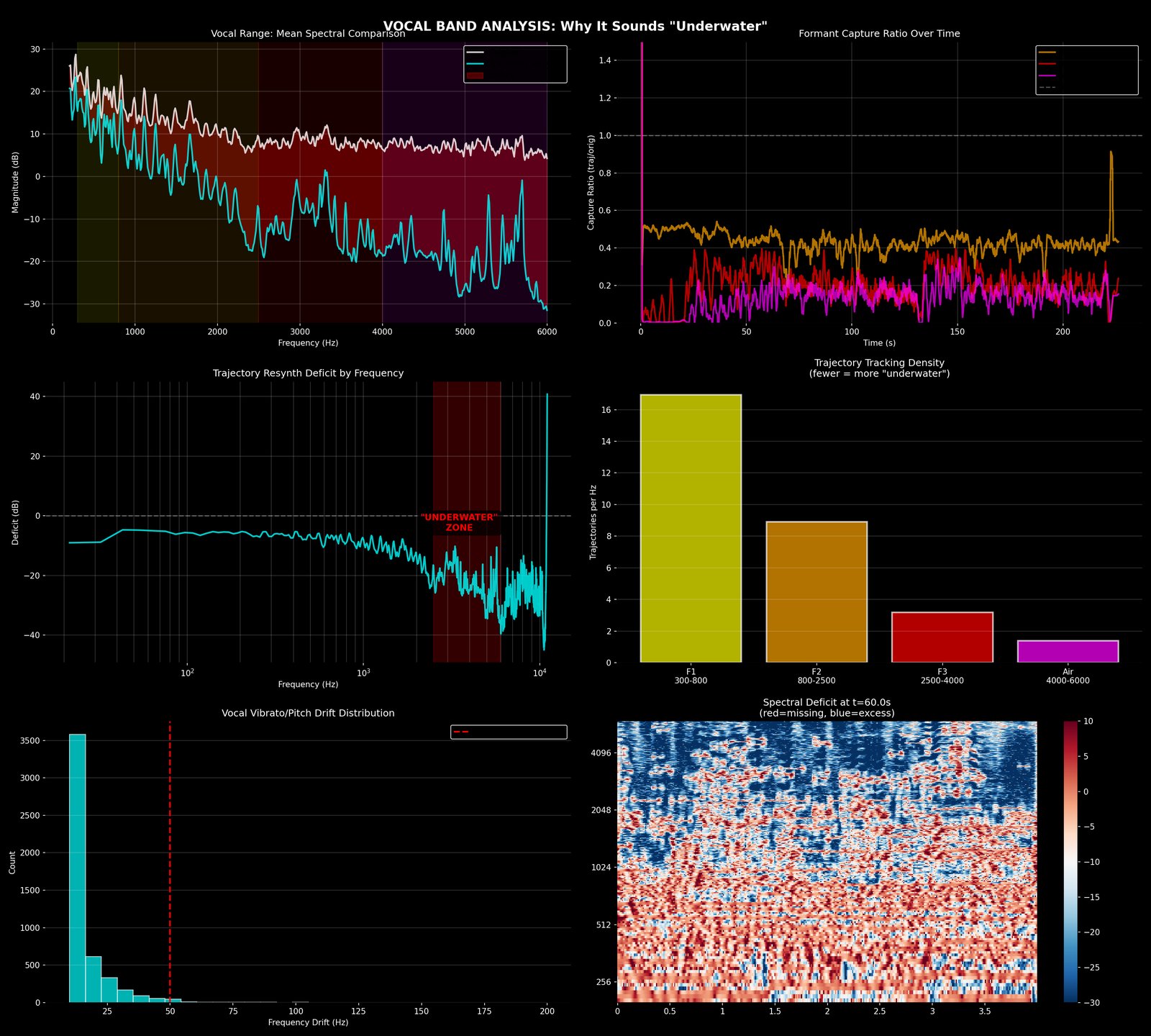
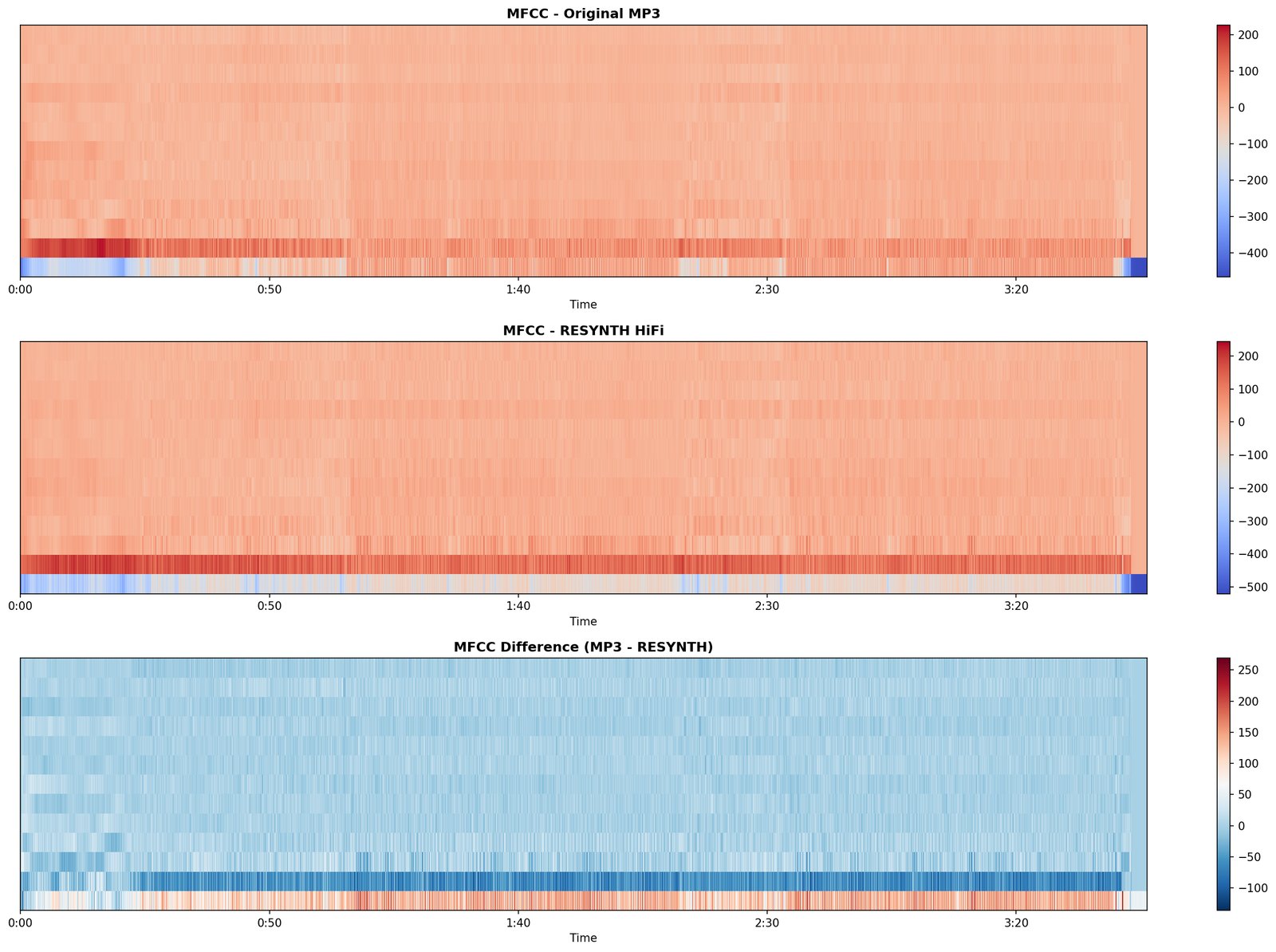
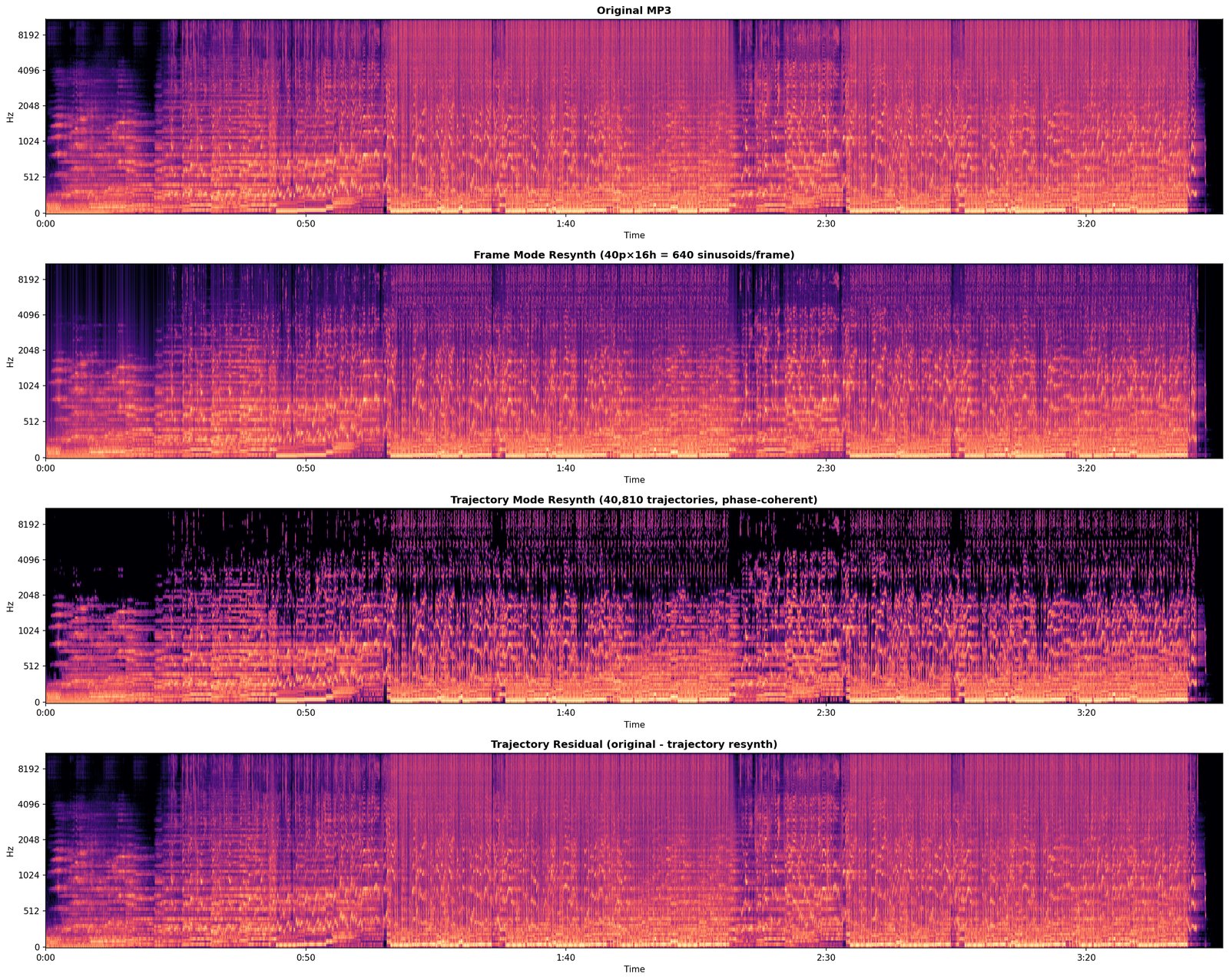
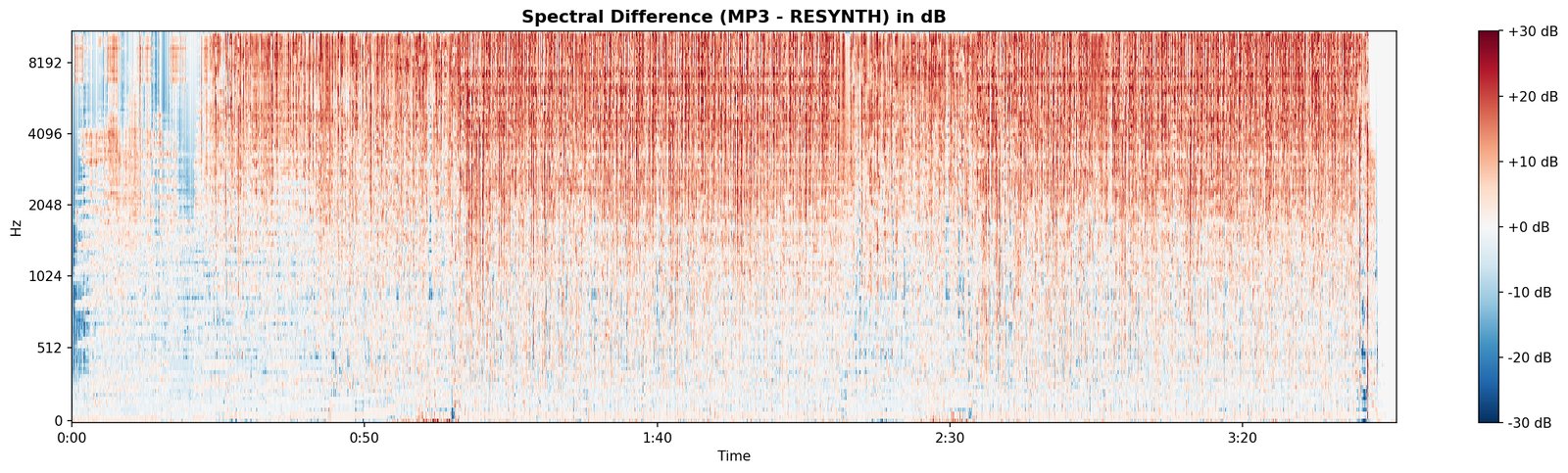
D1 is the hard test. Everything every committed module has claimed to hear, the engine now has to produce sample-level audio for. Whatever the rebuild can’t account for is the residual.
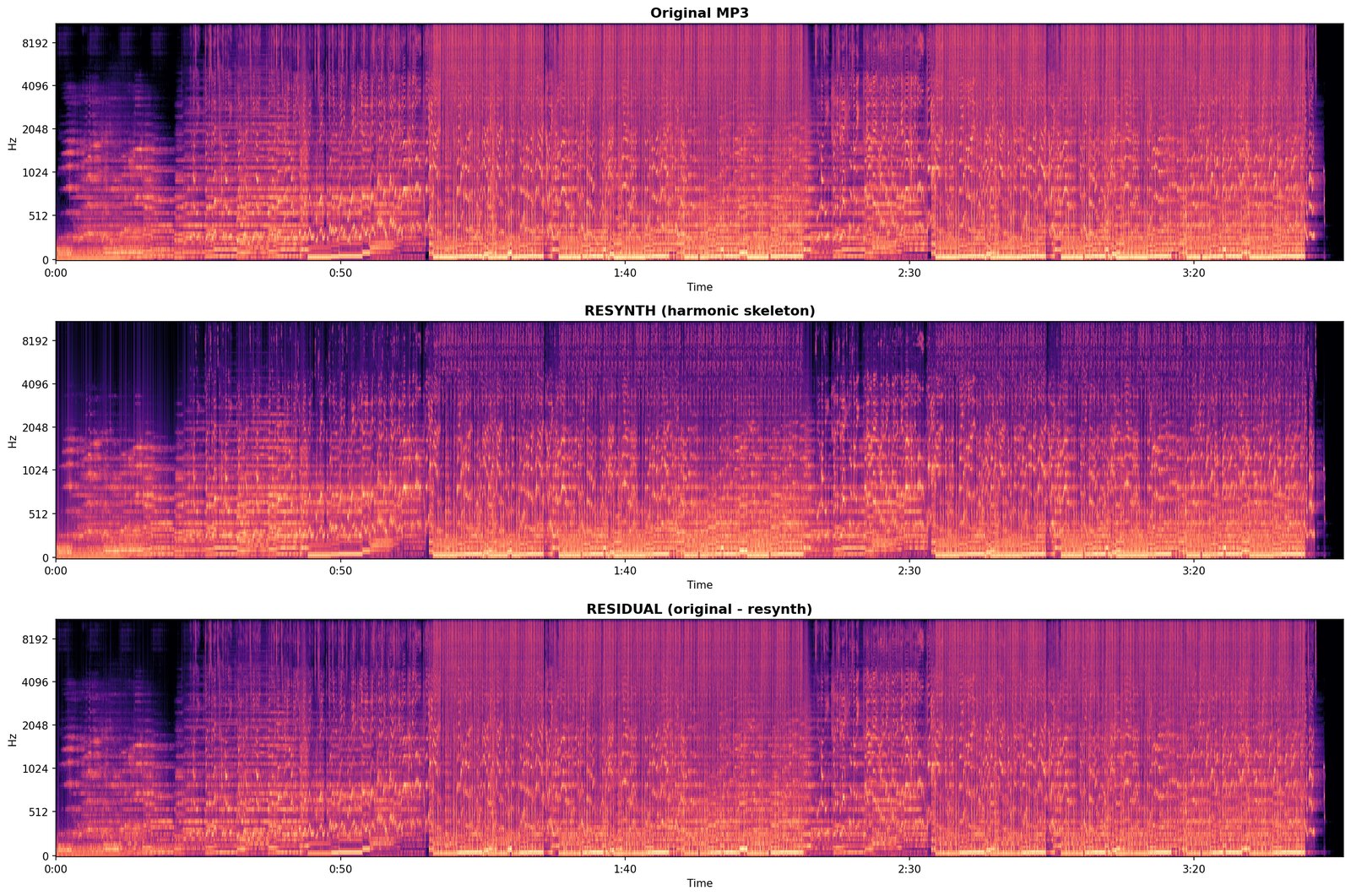
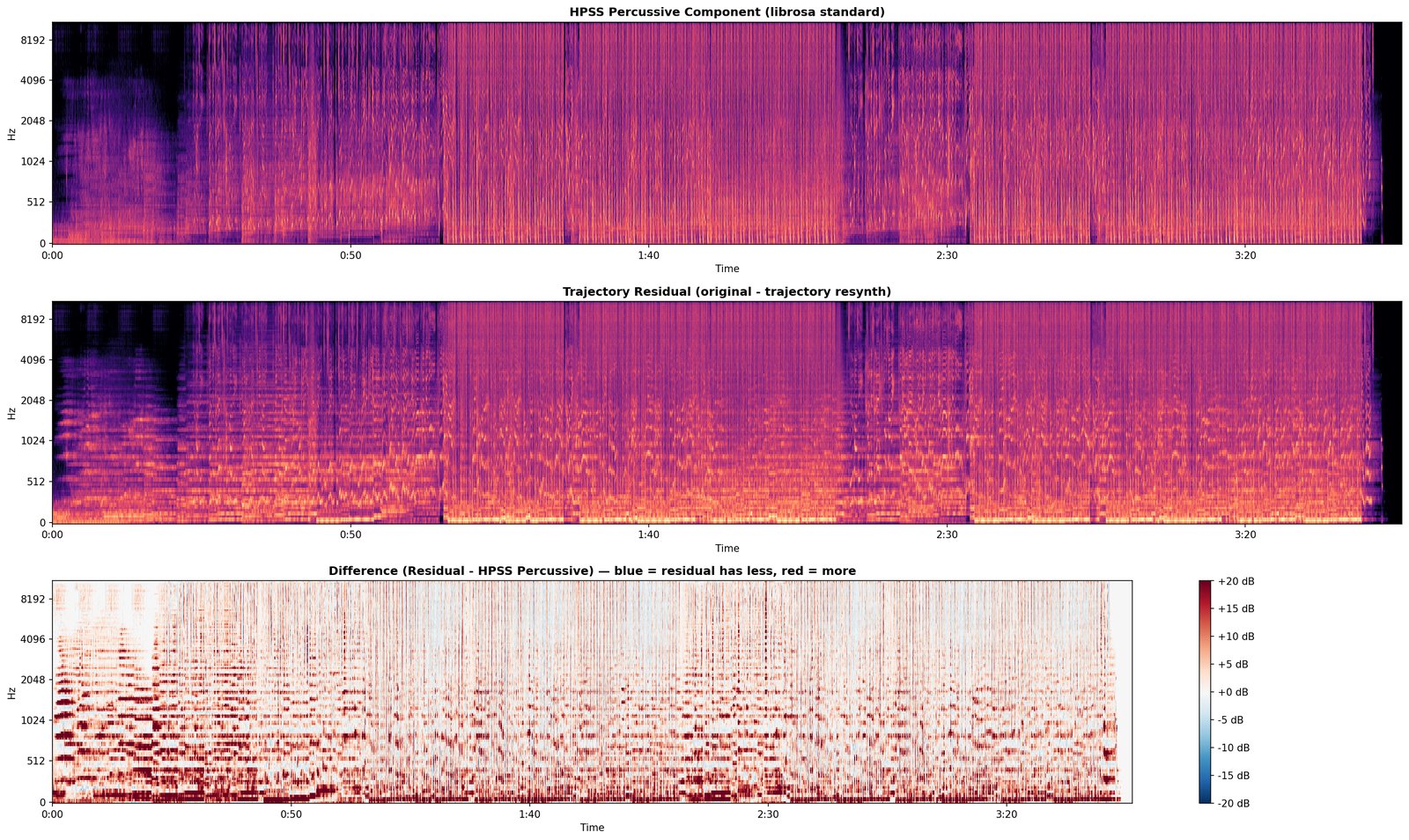
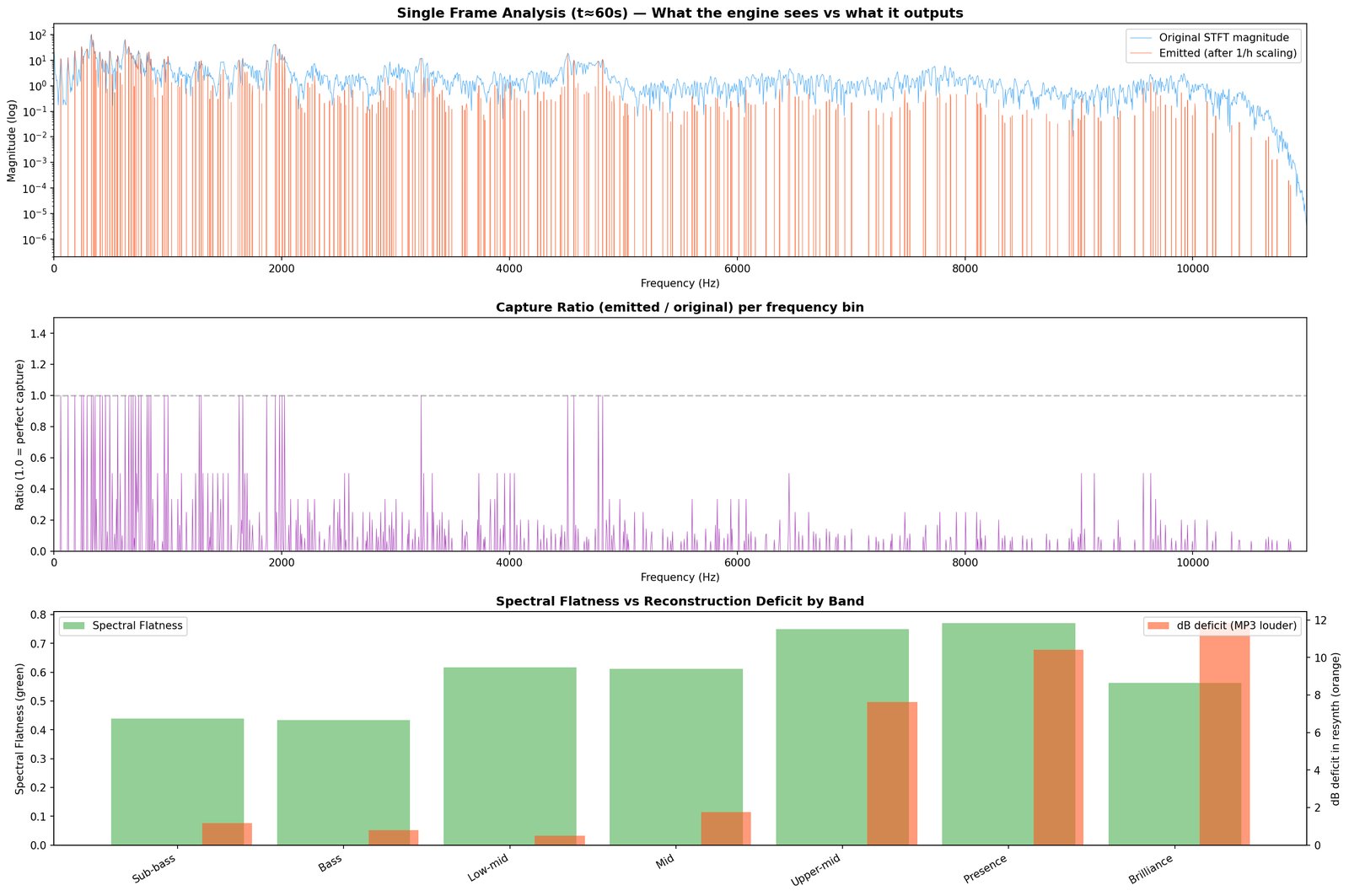
What it writes. Resynthesised .wav, residual .wav, and a written diagnosis (still tentative until 10).
Web / User · 5B · ↔ 5A
Residual review
reception-language match · user listening to the residual
5B asks: does the residual match anything the reception language flagged, and what does the user hear when they listen to it?
What it writes. Reception-match scores per residual region and user listening notes, ready for conference 5.
Conference · 5 · fifth reconciliation
Commit the residual diagnosis
“what's left after subtracting everything we already named — and what is it?”
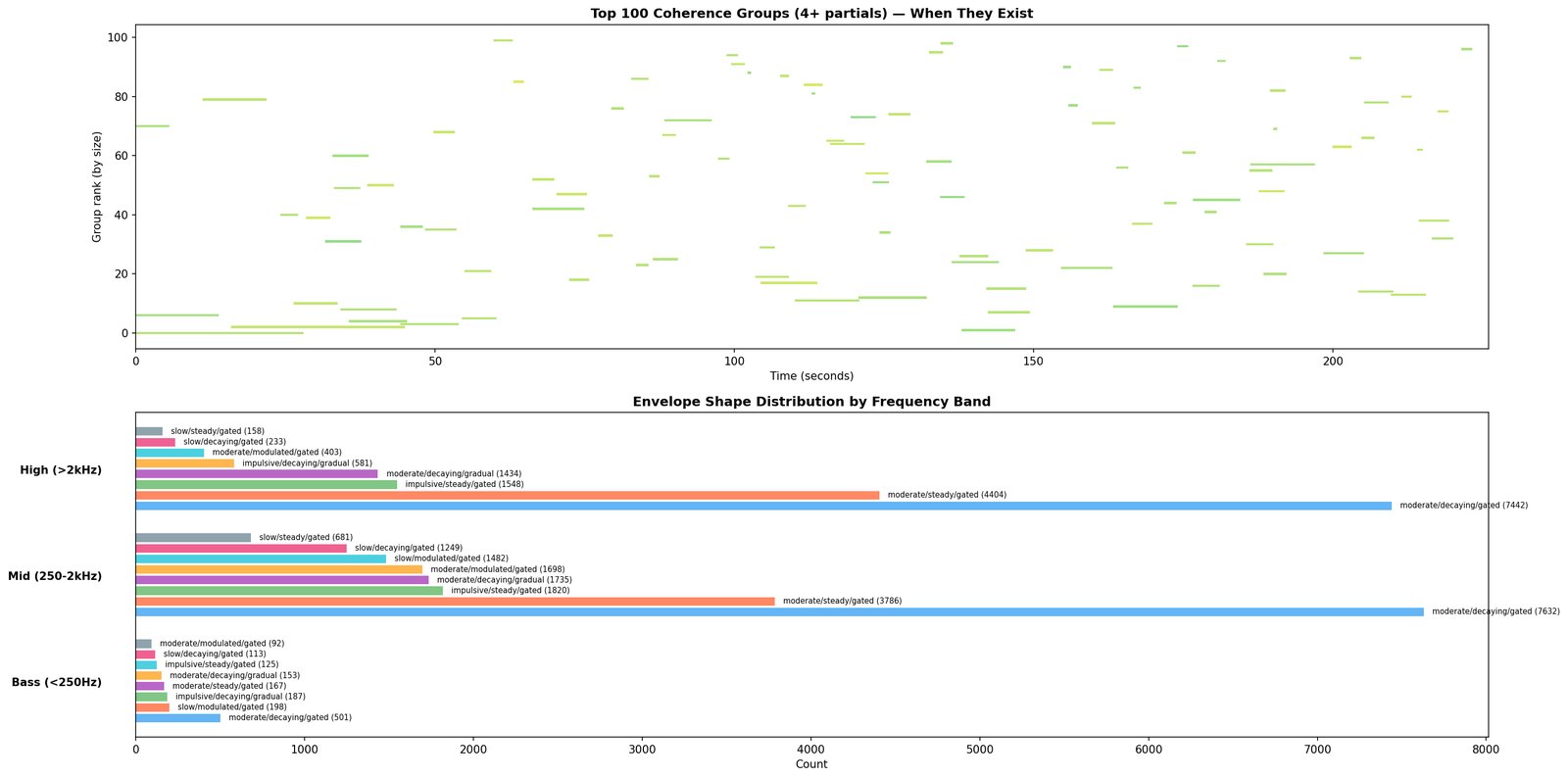
This is where the production tricks live. Everything every earlier conference committed to has been subtracted from the recording. Whatever's left over — the residual — is by definition stuff the engine doesn't yet have names for. The binary side proposes tags for each chunk of leftover energy: a transient that escaped the drum subtraction, a formant the LPC couldn't fully fit, a modulation effect (chorus, flanger, vibrato) the engine doesn't model yet. The web side checks whether any reviewers' language already pointed at it ("muddy lows", "spacious top end"). The user listens for what's missing. Anything that doesn't land in a known bucket stays in "unidentified" — they're the engine's honest backlog.
What it commits. Tagged residual chunks (transient-leak / formant-artefact / modulation-artefact / explained-by-reception / unidentified). The unidentified ones aren't failures — they're the part of the record the engine knows it doesn't know yet. Production tricks hide here.
Binary · 6A · ↔ 6B
Structure, harmony, chroma
self-similarity · chord regions · key estimation
With everything else committed, 6A computes chroma (pitch-class energy per window), the self-similarity matrix, and the chord/key assignments. Like every binary module, 6A is the same engine re-entered — here at the song’s macro scale, on the cleanest residue.
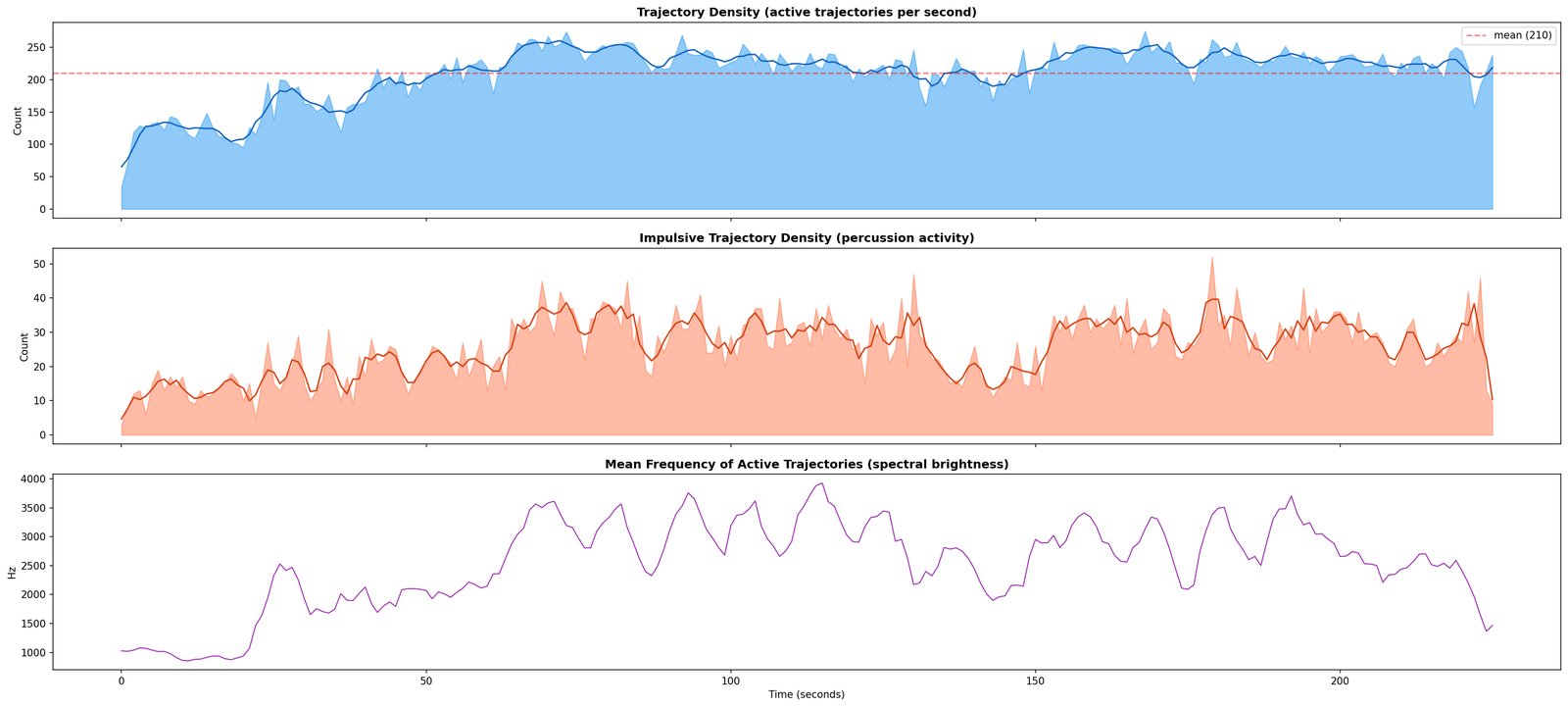
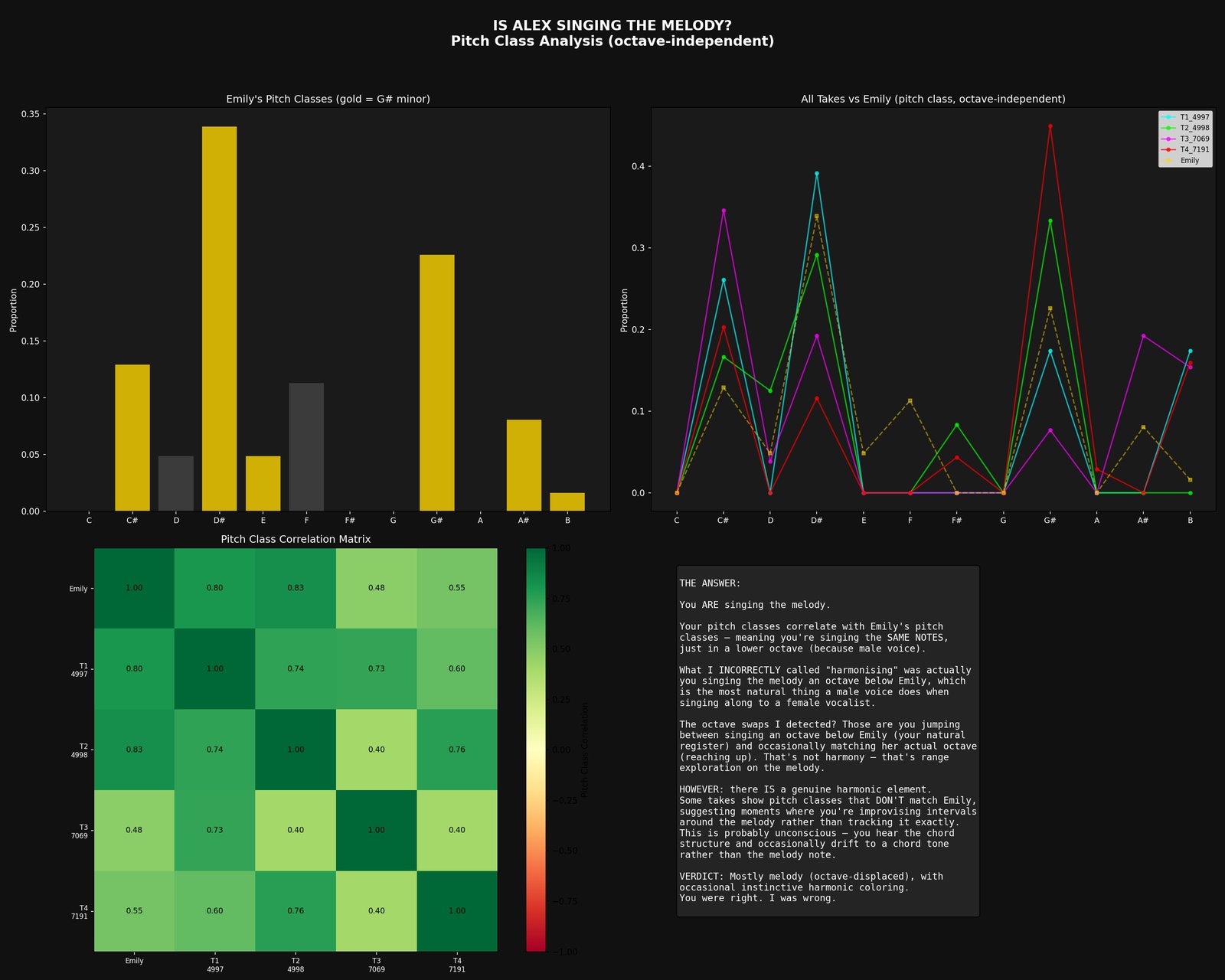
What it writes. Section list (start, end, label, key) and chord regions inside each, held tentatively until 12.
Web / User · 6B · ↔ 6A
Music-theory-granular context
claimed key · genre-typical chord progressions · user corrections
6B asks: what key does the credits or the user say this is in, and does that match the chroma reading?
What it writes. Claimed-key priors, genre priors, and user corrections, ready for conference 6.
Conference · 6 · sixth reconciliation
Commit the structural read
“where do the sections actually sit, what key are they in, and is that really a bridge?”
Final conference. With every individual component named, the engine zooms out to song architecture. The binary side presents what self-similarity and chroma analysis produced — passages that repeat (probably choruses), chord regions per section, an estimated key. The web side weighs that against credit-listed keys and what genre conventions expect ("a verse-chorus pop song with a one-bar pre-chorus is a thing; a five-minute bridge usually isn't"). The user can override anything they hear differently ("that's B minor, not D major"; "this 'bridge' is functionally a pre-chorus"). The structural map drops on top of every earlier commit.
What it commits. A finished structural record. The pipeline now has a complete named decomposition of the recording — spectral, partial, percussive, vocal, residual-audited, structural. Every layer of the engine's read is committed and can be pointed at.